前言
在決定系統性學習 MLOps 之前,我對機器學習的理解停留在「呼叫別人的 API」這個層次。工作上雖然有接觸 AI 相關的服務,但從來沒有從底層去理解模型是怎麼訓練出來的。
這個系列是我從零開始、有系統地走過 ML 核心工具 → 模型架構 → Fine-Tuning → AWS 部署 → 全流程自動化的學習紀錄,總共分五篇。這是第一篇,從最基礎的 NumPy 和 PyTorch 開始。
系列學習路徑總覽
| Phase | 主題 | 核心技術 | 練習目標 |
|---|---|---|---|
| 1(本篇) | ML 核心工具 | NumPy、PyTorch、Autograd | 從零訓練線性迴歸 |
| 2 | 模型架構 | Transformer、Self-Attention、HuggingFace | 載入預訓練模型做推論 |
| 3 | Fine-Tuning | DistilBERT、Trainer API、LoRA | fine-tune 情感分類模型 |
| 4 | AWS 部署 | SageMaker、S3、inference.py | 部署模型為 HTTPS API |
| 5 | 全流程自動化 | Model Registry、Pipeline、CloudWatch | 訓練→評估→部署閉環 |
第一個問題來了:為什麼要學 NumPy?直接學 PyTorch 不行嗎?
答案是:PyTorch 的底層就是矩陣運算。如果你不理解「向量化」和「Broadcasting」,你會在訓練迴圈裡寫出一堆 for loop,不只慢,而且你不會知道自己寫錯了什麼。
背景知識
什麼是 Tensor?
Tensor 是 PyTorch 的核心資料結構,你可以把它想成「可以在 GPU 上跑的 NumPy array」(結構如圖 1 所示)。
純量(Scalar): 0 維 → 一個數字 3.14
向量(Vector): 1 維 → [1, 2, 3]
矩陣(Matrix): 2 維 → [[1, 2], [3, 4]]
Tensor: n 維 → 以上的通稱
圖1 ▲ 從 0D 純量、1D 向量、2D 矩陣,到多維堆疊的 3D Tensor,維度依序延伸
什麼是 Autograd(自動微分)?
訓練模型的核心是「梯度下降」:我們需要知道「如果微調某個參數,Loss 會怎麼變」,這就是梯度。
PyTorch 的 Autograd 會自動幫你算。只要對 tensor 設定 requires_grad=True,每次做運算 PyTorch 都會在背後記錄計算圖,呼叫 .backward() 時自動反推梯度。
訓練迴圈長什麼樣?
所有 ML 訓練程式,核心結構都是這樣:
for epoch in range(epochs):
預測(Forward Pass)
算差距(Loss)
清除舊梯度
反向傳播(Backward Pass)
更新參數(Optimizer Step)Phase 1 實作解析
NumPy 向量化思維
第一個練習是理解「向量化」。同樣的計算,用 for loop 和用矩陣運算,速度差距可以是 100 倍以上:
import numpy as np
# ❌ 慢:for loop
result = []
for x in data:
result.append(x * 2 + 1)
# ✅ 快:向量化
result = data * 2 + 1Broadcasting 讓不同 shape 的矩陣可以直接運算(如圖 2 所示):
A = np.ones((3, 4)) # shape: (3, 4)
b = np.array([1, 2, 3, 4]) # shape: (4,)
# b 自動「廣播」成 (3, 4),不需要手動 tile
result = A + b # shape: (3, 4)
圖2 ▲ 左:for loop 逐筆處理;右:向量化並行運算。下方示意 Broadcasting 如何自動對齊不同 shape 的矩陣
Autograd:看懂梯度怎麼算
給定函數:
對 的導數為:
在 時,梯度 。PyTorch Autograd 幫你自動算(計算圖如圖 3 所示):
import torch
x = torch.tensor(3.0, requires_grad=True)
y = x ** 2 + 2 * x + 1 # y = x² + 2x + 1
y.backward() # 反向傳播
# dy/dx = 2x + 2,在 x=3 時 = 8
print(x.grad) # tensor(8.)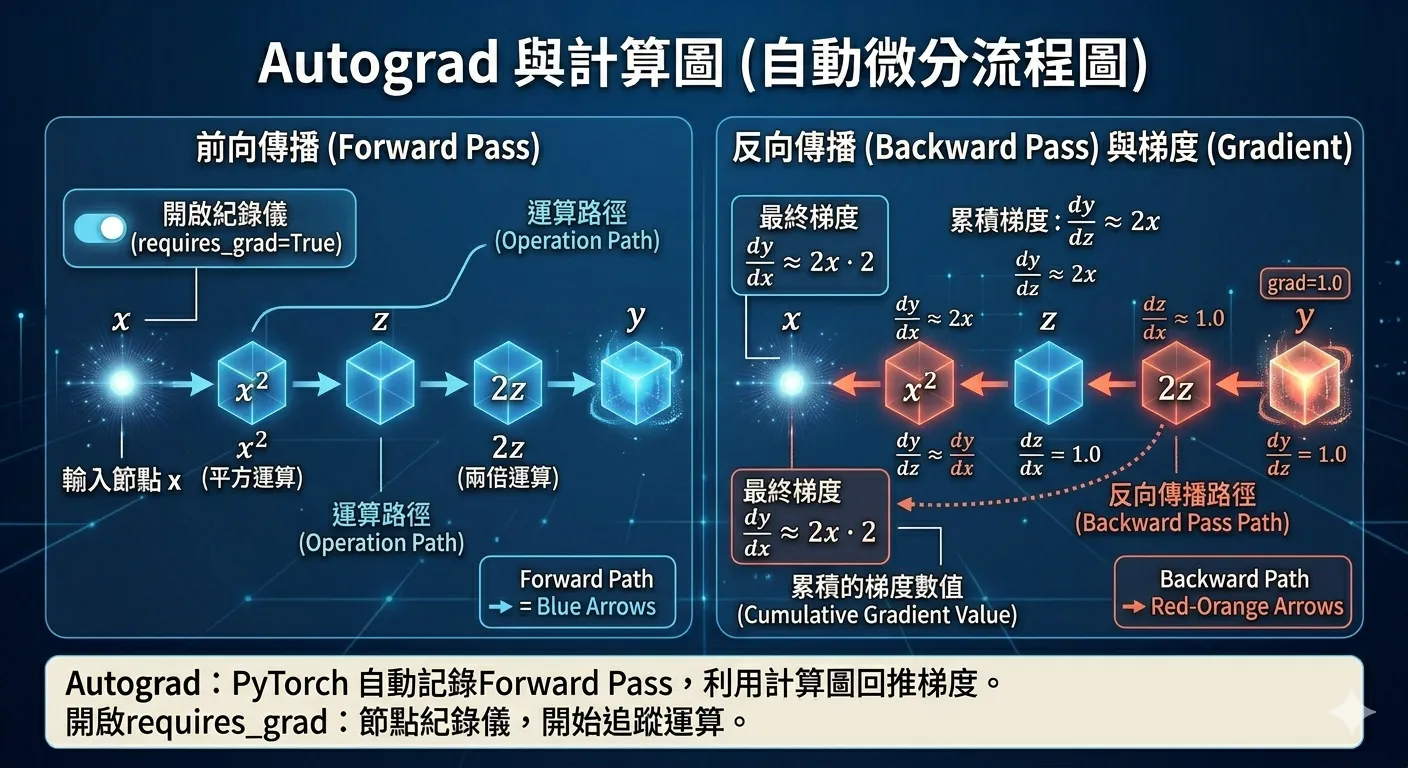
圖3 ▲ PyTorch 在前向傳播時記錄計算圖,呼叫 .backward() 後沿著圖反推每個節點的梯度
這就是整個深度學習的基礎:用梯度告訴模型「往哪個方向調整參數,Loss 才會下降」。梯度下降的參數更新式:
其中 是 learning rate, 是 Loss 對參數的梯度。
完整訓練迴圈
Phase 1 的最終練習是用 PyTorch 從零訓練一個線性迴歸,學習 這條線(訓練迴圈流程如圖 4 所示)。nn.Linear 對應的數學式是:
MSE Loss 衡量預測和真實的差距:

圖4 ▲ 每個 epoch 的五步驟閉環:Forward → Loss → zero_grad → Backward → Optimizer Step
import torch
import torch.nn as nn
# 定義模型
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # y = Wx + b
def forward(self, x):
return self.linear(x)
model = LinearModel()
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 訓練 1000 輪
for epoch in range(1000):
model.train()
y_pred = model(X) # Forward Pass
loss = loss_fn(y_pred, y) # 計算 Loss
optimizer.zero_grad() # 清除舊梯度
loss.backward() # Backward Pass
optimizer.step() # 更新參數訓練完成後,模型學到的 weight ≈ 3.0,bias ≈ 2.0,和真實值吻合。
Dataset 與 DataLoader
現實中資料量很大,不能一次全部塞進模型。PyTorch 提供兩個工具(載入機制如圖 5 所示):
| 工具 | 職責 |
|---|---|
Dataset | 定義「怎麼取第 i 筆資料」 |
DataLoader | 負責批次切分、shuffle、多執行緒載入 |
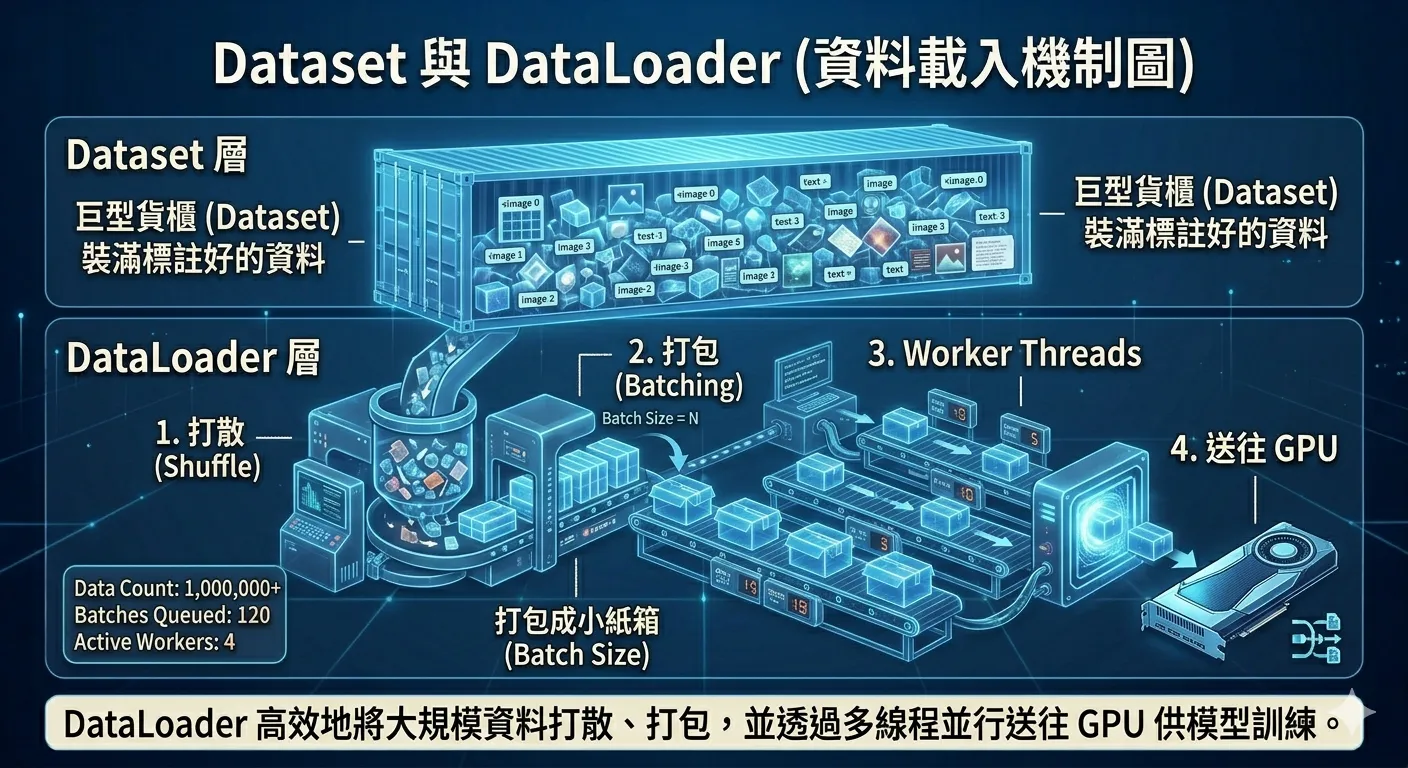
圖5 ▲ Dataset 定義取資料的方式,DataLoader 負責 shuffle、切 batch、多執行緒並行送往 GPU
自定義 Dataset 只需要實作三個方法:
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
self.X = ...
self.y = ...
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]訓練時的完整流程(含 validation):
for epoch in range(epochs):
# 訓練階段
model.train()
for X_batch, y_batch in train_loader:
pred = model(X_batch)
loss = loss_fn(pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 驗證階段
model.eval()
with torch.no_grad():
for X_batch, y_batch in val_loader:
... # 只算 val loss,不更新參數torch.no_grad() 讓推論時不計算梯度,節省記憶體和加速計算。
小結

圖6 ▲ Phase 1 五大核心概念一覽:向量化、Tensor、Autograd、訓練迴圈、Dataset/DataLoader
| 概念 | 重點 |
|---|---|
| 向量化 | 避免 for loop,用矩陣運算取代 |
| Tensor | PyTorch 的核心資料結構,可在 GPU 上運行 |
| Autograd | requires_grad=True + .backward() 自動算梯度 |
| 訓練迴圈 | Forward → Loss → zero_grad → backward → step |
| Dataset/DataLoader | 管理大規模資料的批次載入 |
學完 Phase 1 最重要的觀念:Loss 是唯一的指標,訓練就是「不斷調整參數,讓 Loss 下降」的過程。
下一篇會進入 Phase 2,理解現代 NLP 的核心架構——Transformer 與 Self-Attention。
GitHub
- 完整程式碼:MLOps 學習 repo — phase1